自然言語処理技術による言語教育支援
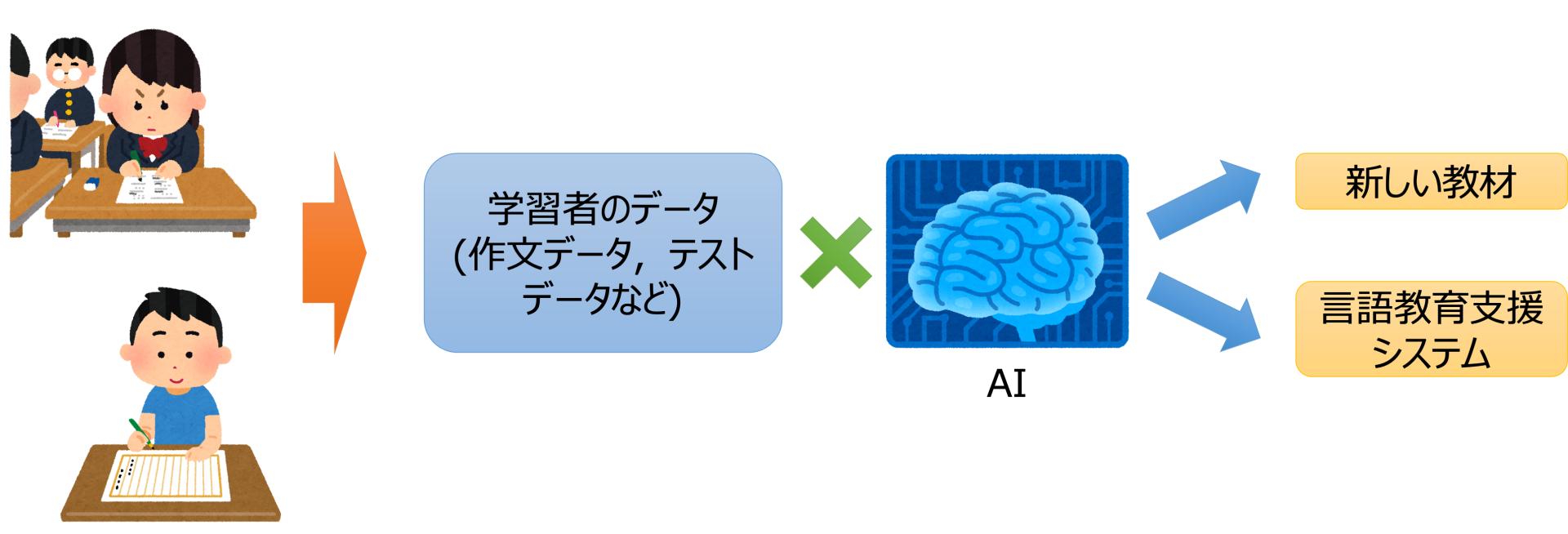
言語学習者や,作文教育などの言語教育に携わる人を支援するシステムの開発に向けて,言語学習者の能力測定や研究に必要となるデータ構築に取り組んでいます.言語学習では,学習者がどのくらい語彙を知っているか,どのくらい文章を書けるかなどを把握する必要があり,本研究テーマでは,他大学や研究機関の研究者と共同で,それらを測るためのテストの方法やそのデータの構築,また,実際の言語学習者の作文データなどの収集やデータを利用した支援システムの構築にも取り組んでいます.
日本語学習者の作文産出過程の分析
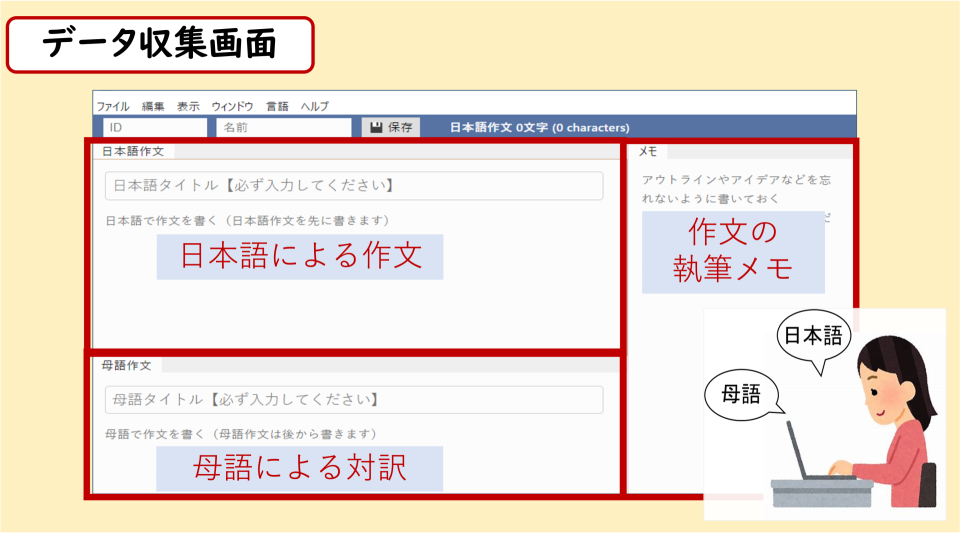
海外の大学で日本語学科などに入学し日本語をゼロから学ぶ日本語学習者の4年間の作文データを収集し,卒業するまでにどのように日本語を習得し,その過程において例えばどのようにして文章が書けるようになるのかの分析に取り組んでいます.収集したデータを用いて,母語の違いによる誤りの傾向の違いの分析や,タイピングの振る舞いの分析,計算機を用いたテキストの内容評価の研究を行っています(国立国語研究所 石黒先生らとの共同研究).
言語学習者の語彙レベル推定
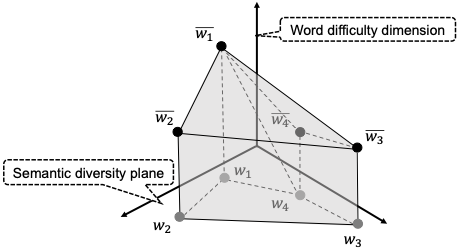
学習者の生産語彙(書いたり話したりするときに使用する語彙)に関する能力を自動的に評価するモデルの研究に取り組んでいます.その能力を測定する方法の一つとして画像に対するキーワードと説明文を記述してもらうPic2PLexというテストを提案しました(東京工業大学 徳永先生らとの共同研究).

ビジネス文書における「よい」文章の分析
ビジネスの現場で用いられるテキストにおいて,どのような特徴が「良い文書」に表れるかを,大量に利用可能であるクラウドソーシングの発注文書を対象としてデータマイニングの手法などを用いて定量的な分析を行いました.結果として,謙譲的な配慮表現が好まれることや一方的な依頼表現は悪影響を与えるといったことがデータから示唆されました.